Monday, October 25, 2010
Latino Decisions
I was embarrassingly unaware of the Latino Decisions project. Good stuff. I recommend a visit.
Thursday, October 21, 2010
The Approval Gap
The current discussion of the enthusiasm gap raises the issue of partisan differences in interest and motivation but also seems to have implications for partisan differences in presidential approval. Specifically, an undercurrent of contemporary discussions of the enthusiasm gap is that Democratic prospects are somewhat handicapped due to relatively anemic support for the President Obama among his own base. While I am not aware of long-term historical data on partisan differences in enthusiasm, it is possible to explore this related issue by examining partisan differences in levels of presidential approval.
In the figures below I use Gallup presidential approval data, focusing on polls taken during October of midterm years from 1946 to 2010 (with the exception of 1946, for which I had to use a poll from September). In terms of overall approval, President Obama's rating currently stands at 45%, just about six points lower than the average of 50.7% during the preceding 16 midterms (below). This puts him in a better position than President Bush was in October of 2006 and slightly better off than Presidents Clinton and Reagan were in 1994 and 1982, respectively.

But the question at hand is whether Obama's approval rating is being dragged down due to flagging levels of support from his base. Of course, it is expected that presidents enjoy an advantage among their own partisans, so the best way to answer this question is to examine partisan trends in approval over time. The figure below shows, as expected, presidents do best with their own partisans, worst with the opposition party, and somewhere in between with independents. No surprises there. But there are a couple of noteworthy observations to make about pattern in 2010.

First, it is just not true that Obama has a problem with his base. In fact, compared to previous presidents, he is doing relatively well with his base, with an approval rating among Democrats (80%) that is somewhat higher than the average level of support other presidents got from their own partisans (76%). Obviously, though, running strong among the base is not enough, as President Bush actually did slightly better among his base in 2006, when the Republicans lost 30 House seats. Second, in sharp contrast to his own base, the level of approval among the opposition Republicans (7%) represents an all time low during this time period, rivaled only by president Bush's approval among Democrats in in 2006 (9%). Together, 2006 and 2010 represent a substantial negative shift in support among opposition partisans, one that fits with the general pattern of increased partisanship that has been observed by others. Finally, the president is also running about 10 points behind the long-term average among independents, coming in at 40% approval. While it may be expected that presidents fare poorly among opposition partisans, this tepid level of support among independents--a group that is typically down-the-middle on approval--is taking a toll on the overall level of approval.
Even though the president is doing relatively well among his own partisans, the patterns shown above do jibe fairly well with contemporary discussions of the enthusiasm gap, at least in so far as they show that Republicans are much more united in their opposition to the president than Democrats are in their support of him.
In the figures below I use Gallup presidential approval data, focusing on polls taken during October of midterm years from 1946 to 2010 (with the exception of 1946, for which I had to use a poll from September). In terms of overall approval, President Obama's rating currently stands at 45%, just about six points lower than the average of 50.7% during the preceding 16 midterms (below). This puts him in a better position than President Bush was in October of 2006 and slightly better off than Presidents Clinton and Reagan were in 1994 and 1982, respectively.

But the question at hand is whether Obama's approval rating is being dragged down due to flagging levels of support from his base. Of course, it is expected that presidents enjoy an advantage among their own partisans, so the best way to answer this question is to examine partisan trends in approval over time. The figure below shows, as expected, presidents do best with their own partisans, worst with the opposition party, and somewhere in between with independents. No surprises there. But there are a couple of noteworthy observations to make about pattern in 2010.

First, it is just not true that Obama has a problem with his base. In fact, compared to previous presidents, he is doing relatively well with his base, with an approval rating among Democrats (80%) that is somewhat higher than the average level of support other presidents got from their own partisans (76%). Obviously, though, running strong among the base is not enough, as President Bush actually did slightly better among his base in 2006, when the Republicans lost 30 House seats. Second, in sharp contrast to his own base, the level of approval among the opposition Republicans (7%) represents an all time low during this time period, rivaled only by president Bush's approval among Democrats in in 2006 (9%). Together, 2006 and 2010 represent a substantial negative shift in support among opposition partisans, one that fits with the general pattern of increased partisanship that has been observed by others. Finally, the president is also running about 10 points behind the long-term average among independents, coming in at 40% approval. While it may be expected that presidents fare poorly among opposition partisans, this tepid level of support among independents--a group that is typically down-the-middle on approval--is taking a toll on the overall level of approval.
Even though the president is doing relatively well among his own partisans, the patterns shown above do jibe fairly well with contemporary discussions of the enthusiasm gap, at least in so far as they show that Republicans are much more united in their opposition to the president than Democrats are in their support of him.
Monday, October 18, 2010
Senate and Gubernatorial Update
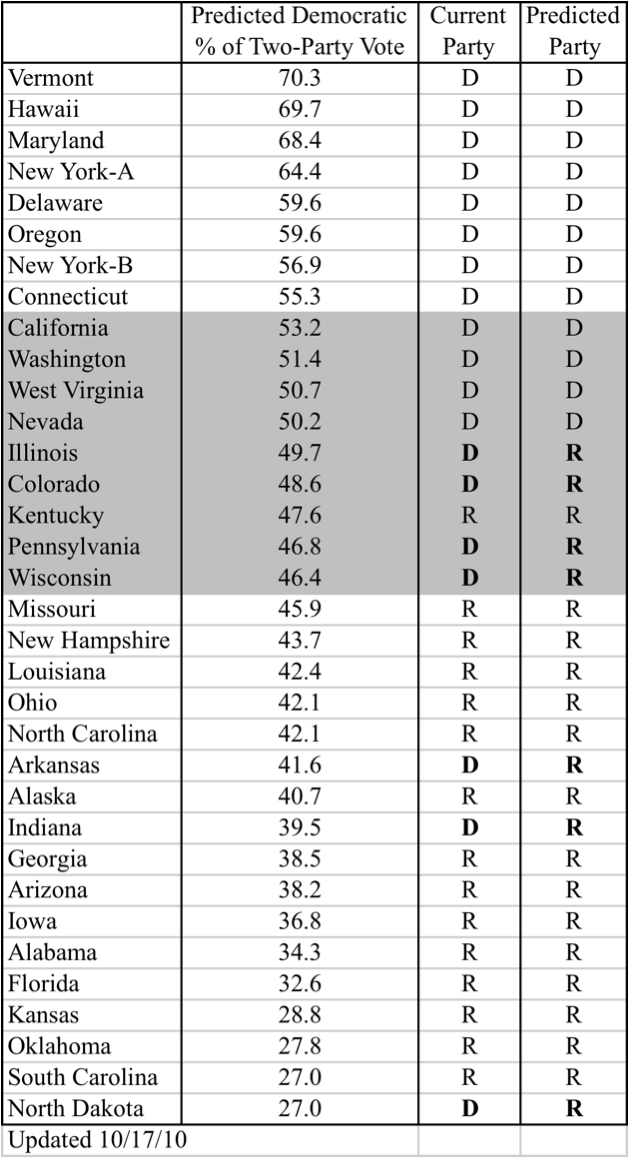
I've updated my projections for Senate and Gubernatorial outcomes, based on the historical relationship between polls and actual election outcomes in 2006 and 2008. The new tables (below) rank order the states by the magnitude of the predicted Democratic vote, and the shaded areas represent the closest predicted outcomes.
Here's where things stand right now. Based on point estimates alone, I project a Republican a gain of seven seats in the Senate and five governorships. While I don't see any potential Republican losses in the Senate, their gains in the gubernatorial races are blunted somewhat by expected losses of several currently Republican governorships: California, Connecticut, Florida, Hawaii, Minnesota, Rhode Island. Many of these projected outcomes, as well as some of the Democrat-to-Republican switches, are razor thin, so any sort of unspecified error that systematically biases projects toward one of the parties could produce significantly different aggregate results. It's also worth noting that two races, Colorado and Rhode Island, have strong independent candidacies that could upset the Democratic candidates, even if they beat their Republican rivals.
On the Senate side, I don't see a lot to suggest that the picture will turn out very different from the projection of seven Democratic losses. To be sure, two seats pegged as switching, Illinois and Colorado, are close enough that a small change in poll results could push them into the Democratic hold column. At the same time, though, a couple of the projected Democratic holds, Nevada and West Virginia, could easily turn into Republican pickups.
Note that all projections are based on polling averages from forty-five days prior to the election (September 18) and that polling data for the models and for the 2010 elections are from pollster.com.
Here's where things stand right now. Based on point estimates alone, I project a Republican a gain of seven seats in the Senate and five governorships. While I don't see any potential Republican losses in the Senate, their gains in the gubernatorial races are blunted somewhat by expected losses of several currently Republican governorships: California, Connecticut, Florida, Hawaii, Minnesota, Rhode Island. Many of these projected outcomes, as well as some of the Democrat-to-Republican switches, are razor thin, so any sort of unspecified error that systematically biases projects toward one of the parties could produce significantly different aggregate results. It's also worth noting that two races, Colorado and Rhode Island, have strong independent candidacies that could upset the Democratic candidates, even if they beat their Republican rivals.
Gubernatorial Forecasts
 |
Senate Forecasts
 |
Monday, October 11, 2010
Polls and Gubernatorial Elections
Despite the fact that the American public (or at least the politically interested among us) are voracious consumers of publicly available polls, it is not uncommon to hear a refrain something along the lines of "you can't trust polls." Yet, polls abound and play a prominent role in all manner of political prognostications. What I've tried to do in my earlier posts on House and Senate elections is provide a concrete illustration of how polls are related to outcomes. Hopefully, this helps make it clear why polls are so important to political forecasters.
Today, I turn to gubernatorial elections, which, perhaps not too surprisingly, follow a pattern very similar to senate polls. In keeping with the earlier posts, I focus here on how well "out-of-sample" forecasts account for actual outcomes. The logic is that you can't predict the 2010 outcomes based on the observed relationship between polls and outcomes in 2010 because you won't know what tht relationship is until after the election. The solution is to use the observed relationship between polls and outcomes in other years to make predictions prior to the election. These are out-of-sample forecasts.
The figure below shows how well the poll-based out-of-sample predictions track with actual outcomes in forty-five gubernatorial elections from 2006 (34) and 2008 (11). To generate the 2008 estimates, I regressed 2006 outcomes on 2006 polling averages over the last forty-five days of the campaign and used the estimates of that relationship (constant and slope) to predict 2008 outcomes using 2008 polling data. I then used the relationship for the 2008 polls and outcomes, along with the polling data from 2006, to forecast the 2006 outcomes. (Note: Data were generously provided by Pollster.com).
 This is a very strong relationship and speaks to the potency of polls (or at least polling averages) as predictors of elections. The correlation between the out-of-sample forecasts and the actual outcomes in 2006 and 2008 is .99 and the model predicted the wrong winner in just two of the cases. Certainly, many of the forecasts are very close to 50% and could easily end of calling the wrong winner, even if the point estimate is of by just a couple of percentage points. But the pattern found here, in conjunction with that found earlier for Senate elections, suggests that candidates trailing significantly in the polls are not likely to win.
This is a very strong relationship and speaks to the potency of polls (or at least polling averages) as predictors of elections. The correlation between the out-of-sample forecasts and the actual outcomes in 2006 and 2008 is .99 and the model predicted the wrong winner in just two of the cases. Certainly, many of the forecasts are very close to 50% and could easily end of calling the wrong winner, even if the point estimate is of by just a couple of percentage points. But the pattern found here, in conjunction with that found earlier for Senate elections, suggests that candidates trailing significantly in the polls are not likely to win.
So, what does this augur for the 2010 gubernatorial election? To answer this, I used estimates of the relationship between polls and outcomes in the 2006 and 2008 gubernatorial elections to generate a set of predictions for 2010. A couple of things to note. First, these estimates are based on polls taken during the forty-five days preceding the election. This means that I don't have estimates for all states holding elections, though I assume I will before too long. Second, these predictions are not final and will change as new data come in. I'll try to update the predictions at least once a week. Finally, I present point estimates only. It goes without saying that predictions of close outcomes are far more likely than predictions of blowouts to call the wrong winner. But, at the end of the day, you have to call it one way or the other and the point estimate is the best guess.
Here are the predictions:

Based on predictions for the states for which I have data, the model predicts ten seats switching from Democrat to Republican and five seats switching from Republican to Democrat, for a net Republican gain of five governorships. The highlighted area simply indicates those states with the closest outcomes, where an error of just a couple of points could change the overall picture. Two states that haven't yet had polls in the forty-five day pre-election window, Kansas and Tennessee, have earlier polls that also indicate a strong likelihood of a Democrat-to-Republican flip, making the picture even more bleak for the Democrats.
Today, I turn to gubernatorial elections, which, perhaps not too surprisingly, follow a pattern very similar to senate polls. In keeping with the earlier posts, I focus here on how well "out-of-sample" forecasts account for actual outcomes. The logic is that you can't predict the 2010 outcomes based on the observed relationship between polls and outcomes in 2010 because you won't know what tht relationship is until after the election. The solution is to use the observed relationship between polls and outcomes in other years to make predictions prior to the election. These are out-of-sample forecasts.
The figure below shows how well the poll-based out-of-sample predictions track with actual outcomes in forty-five gubernatorial elections from 2006 (34) and 2008 (11). To generate the 2008 estimates, I regressed 2006 outcomes on 2006 polling averages over the last forty-five days of the campaign and used the estimates of that relationship (constant and slope) to predict 2008 outcomes using 2008 polling data. I then used the relationship for the 2008 polls and outcomes, along with the polling data from 2006, to forecast the 2006 outcomes. (Note: Data were generously provided by Pollster.com).

So, what does this augur for the 2010 gubernatorial election? To answer this, I used estimates of the relationship between polls and outcomes in the 2006 and 2008 gubernatorial elections to generate a set of predictions for 2010. A couple of things to note. First, these estimates are based on polls taken during the forty-five days preceding the election. This means that I don't have estimates for all states holding elections, though I assume I will before too long. Second, these predictions are not final and will change as new data come in. I'll try to update the predictions at least once a week. Finally, I present point estimates only. It goes without saying that predictions of close outcomes are far more likely than predictions of blowouts to call the wrong winner. But, at the end of the day, you have to call it one way or the other and the point estimate is the best guess.
Here are the predictions:

Based on predictions for the states for which I have data, the model predicts ten seats switching from Democrat to Republican and five seats switching from Republican to Democrat, for a net Republican gain of five governorships. The highlighted area simply indicates those states with the closest outcomes, where an error of just a couple of points could change the overall picture. Two states that haven't yet had polls in the forty-five day pre-election window, Kansas and Tennessee, have earlier polls that also indicate a strong likelihood of a Democrat-to-Republican flip, making the picture even more bleak for the Democrats.
Thursday, October 7, 2010
Jay's Gubernatorial Model
Jay DeSart has some gubernatorial forecasts up on his site. I will have mine up in the next few days. Given our shared history in these matters, however, I suspect Jay and I are using the same(ish) model (more details, Jay!).
Tuesday, October 5, 2010
Are Polls Junk?
Given the sheer volume of polling data made public every day, and given that there sometimes seems to be a lot of variation in what the polls say about individual races, it is not surprising to hear doubts expressed about the overall quality of political polling. Charlie Cook, for instance recently expressed a preference for candidate or party-sponsored polls and a skepticism of "independent" polling, even referring to academic polls and those sponsored by local media as "dime store junk." At the same time, though, polls are pretty useful in predicting outcomes. In earlier posts, I've shown that both House and Senate outcomes track very closely with aggregated polls, and Nate Silver also touts the predictive power of polls, using them as a central component in his forecasting models.
My point in this post is not to sort out which types of polls are more accurate than others, though that might come in a later post. Instead, I'm interested in looking at the average rate of polling error. Although there are a lot of things one could look at to judge the quality of a poll (question wording, sampling method, etc.), my guess is that most people focus on the bottom--how close the poll finding is to the election outcome--when judging trial-heat polls. For better or worse, this is likely to be the case. Toward that end, I examine the error in Senate, House, and gubernatorial polls taken in the last fifteen days of the 2006 and 2008 campaigns.
The histograms below show the distribution of polling error across offices and years. In all of the figures, I compare the Democratic percent of the two-party vote result to the Democratic percent of the two-party poll result. Data for all of these graphs come from pollster.com.






To be sure, there are differences across years and across level of office, but the overall picture is not one of wildly inaccurate polls. Some of the key findings are:
- The statewide polls in Senate and gubernatorial elections are generally more accurate than district-level House polls. House polls in 2008 had the highest error rate.
- Most polls (90% of Senate polls, 88% of gubernatorial polls, and 81% of house polls) are within five points of the actual outcome.
- Overall, the election outcomes fall within margin of error of individual polls 79% of the time. Theoretically, this should happen 95% of the time.
Subscribe to:
Posts (Atom)